
הטוקן (Token): היחידה האטומית של ה-AI הגנרטיבי
כדי להבין את היכולות – ואת המגבלות – של בינה מלאכותית גנרטיבית, חיוני להבין תחילה את אבן הבניין הבסיסית שלה.
מודלי שפה אינם "קוראים" טקסט כפי שבני אדם קוראים אותו. הם מעבדים רצפים של מספרים המייצגים יחידות משמעות הנקראות "טוקנים".
הבנת מנגנון זה היא הבסיס לכל יישום אסטרטגי של AI בארגון.
מהו טוקן? המעבר ממילים למספרים
הבנת יכולות הבינה המלאכותית מחייבת הכרת יחידת הבסיס: הטוקן. מודלי שפה מתקדמים אינם מעבדים טקסט כיחידות שפה אנושיות. הם פועלים על רצפי מספרים המייצגים יחידות משמעות סטטיסטיות.
תהליך הטוקניזציה: המעבר לייצוג מספרי
מודל ה-AI עיוור לשפה כפי שאנו מכירים אותה. לפני עיבוד במודלים מתקדמים, הטקסט עובר טוקניזציה. תהליך זה מפרק טקסט ליחידות משמעות מינימליות עבור המודל.
- מילה שלמה (באנגלית: "Hello")
- חלק ממילה או הברה (כמו הסיומת "ing" במילה "Running")
- סימן פיסוק בודד (כמו פסיק או נקודה)
- אפילו רווח
המחשה טכנית: מטקסט לטוקנים, ומטוקנים למספרים
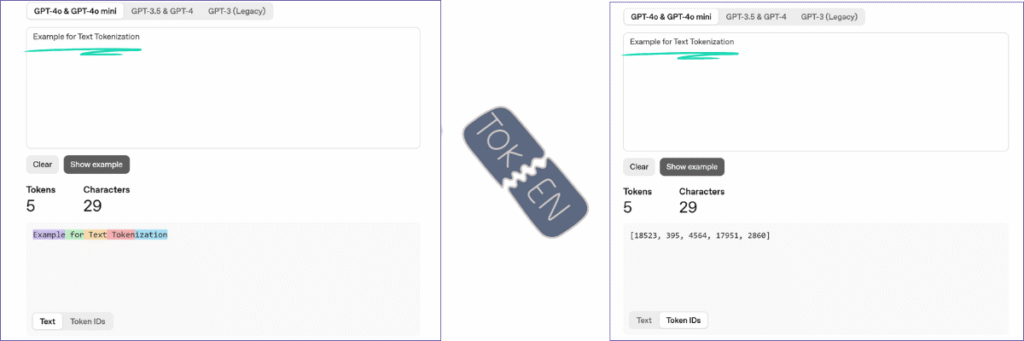
כדי להבין כיצד המודל "רואה" את המידע בפועל, נבחן דוגמה מתוך כלי הטוקניזציה של OpenAI.
המחשה טכנית: מטקסט לטוקנים
בהזנת המשפט "Example for Text Tokenization", המערכת מזהה חמש יחידות בסיס. מילים ארוכות מפוצלות לצורך אופטימיזציית חישוב. המילה "Tokenization" מפוצלת לשני טוקנים נפרדים.
המרת טוקנים למזהים מספריים
כל טוקן מומר מיידית למזהה מספרי ייחודי (Token ID). בדוגמה המוצגת, המשפט הופך לרצף המספרים: [18523, 395, 4554, 17951, 2868]. רשימה זו היא הקלט היחיד המשמש את המודל לחישובים.
Open AI Tokenizer – קישור להתנסות בסוף המאמר
המנוע הסטטיסטי: ניבוי הסתברותי
לאחר שהבנו שהמודל מקבל רצף של מספרים, עולה השאלה: מה הוא עושה איתם? חשוב להפנים: מודל שפה אינו "חושב" ואין לו מאגר תשובות מוכן. הוא פועל כמכונת ניבוי סטטיסטית.
תהליך היצירה הוא אוטו-רגרסיבי (Autoregressive):
- המודל מקבל כקלט רצף של מזהים מספריים (הטוקנים של השאילתה שלכם).
- הוא מנתח את הרצף ומחשב סטטיסטית מהו המספר (הטוקן) הבא הסביר ביותר להופיע אחריו.
- ברגע שנבחר טוקן, הוא מתווסף לרצף הקיים, והתהליך חוזר חלילה לניבוי הטוקן שאחריו.
זו הסיבה שניסוח השאילתה (Prompt Engineering) הוא קריטי: הטוקנים הראשונים שאתם מספקים קובעים את מרחב ההסתברויות של המודל להמשך התשובה.
השלכות מעשיות של מנגנון הטוקנים
הבנת המנגנון הטכני מובילה ישירות לשתי תובנות ניהוליות מרכזיות:
- כלכלת המידע: מכיוון שספקיות ה-AI משקיעות משאבי מחשוב עצומים בעיבוד כל טוקן (כל מספר ברצף), התמחור מבוסס על נפח הטוקנים הכולל בשלב הקלט ובשלב הפלט.
- זיכרון העבודה (Context Window): למודל יש מגבלה לכמות הטוקנים שהוא יכול "לזכור" ולעבד בבת אחת. זהו "חלון ההקשר". אם נזין למודל מסמך שאורכו חורג ממגבלת הטוקנים שלו, הוא פשוט "ישכח" את תחילת המידע (המספרים הראשונים ברצף), מה שיוביל לתוצאות שגויות.
טוקנים בבינה מלאכותית: סיכום והמלצה להתנסות
המעבר מתפיסת ה-AI כ"קסם" להבנתו כמערכת הנדסית מתחיל בטוקן. כדי להמחיש את הנושא באופן המוחשי ביותר, אני ממליץ לצוותים המקצועיים להתנסות בכלי ה-Tokenizer הרשמיים (כדוגמת זה שהוצג במאמר). הזינו לשם טקסטים ארגוניים שונים, וראו במו עיניכם כיצד המכונה מפרקת את השפה האנושית לרצפים של יחידות חישוב מספריות.
Tokenizer – OpenAI API








תגובה אחת