סדרת מאמרים: Finance 4.0 ו-AI במחלקות כספים
| קישור | הסבר כללי |
|---|---|
| Finance 4.0: המעבר לארכיטקטורת ערך אסטרטגית בעידן ה-AI | מבוא ותפיסת עולם על חדשנות ובינה מלאכותית במחלקת הכספים. |
| Semantic Layer: הלב הפועם של ה-Finance 4.0 וניהול דאטה מודרני | איך מייצרים שכבת דאטה עם משמעות בדאטה עבור ה-AI. |
| Finance 4.0: המדריך המלא ל-ETL ו-ELT במחלקת הכספים המודרנית | אוטומציות בתהליכי אינטגרציה של דאטה. |
| 👈 את/ה כאן | משנים תפיסה ועוברים מחשיבה של גריד באקסל לארכיטקטורת דאטה חכמה ומודרנית. |
| CDAIO: איך מחברים בין Data-Driven ל-AI כדי לייצר ערך עסקי אמיתי | CDAIO (Chief Data & AI Officer) – תפקיד אסטרטגי המחבר בין דאטה, בינה מלאכותית וערך עסקי, ואחראי להובלת ארכיטקטורת נתונים, שימושי AI ויישומם בפועל במחלקות כספים ובארגון כולו. |
| Microsoft Fabric: פלטפורמת דאטה אחידה בעידן הבינה המלאכותית | פלטפורמה לדוגמא ליישום חדשנות בדאטה בארגונים שרוצים להוביל. |
מאמרי הסדרה כוללים חוברות הדרכה מפורטות, תרשימים ודוגמאות יישומיות – המיועדות למנהלים ולצוותי כספים.

Database Thinking: הקדמה
השיחה על Finance 4.0 או בינה מלאכותית במחלקות כספים נוטה לעיתים קרובות להתמקד בכלים נוצצים. האמת היא שהחסם הגדול ביותר לא נמצא בענן או בשרתים – הוא נמצא אצלנו בראש. במשך עשורים הורגלנו לחשוב במונחים של “תאים” וקואורדינטות, תפיסה שמעניקה אשליית שליטה אך מייצרת “חוב טכני” אדיר בכל דו”ח. כדי לפרוץ את תקרת הזכוכית הזו ולהטמיע יכולות AI אמיתיות, עלינו לאמץ Database Thinking. זוהי הדרך היחידה לעבור מניהול “איי מידע” מבודדים לבניית תשתית נתונים רובסטית שתשרת את הארגון שנים קדימה.
השבר הפסיכולוגי: מהגריד המוכר אל ההפשטה של הסט
המשיכה הפסיכולוגית ל-Microsoft Excel נובעת מהיותו רשת (Grid) דו-ממדית המדמה את ספרי החשבונות הידניים של העבר. כל תא הוא ישות עצמאית, ואנחנו “רואים” את המידע בעיניים. אלא שהגמישות הזו היא חרב פיפיות. הלוגיקה העסקית קבורה בתוך תאים אקראיים, ושינוי מבני קל שובר את כל המערכת.
אימוץ Database Thinking דורש מאיתנו לוותר על הביטחון שבקונקרטיות לטובת עוצמת ההפשטה (Abstraction). במסד נתונים, אנחנו לא שואלים “מה יש בשורה 3”, אלא מגדירים שאילתות לוגיות על קבוצות מידע (Set-Based Thinking). בפרדיגמה הזו, סדר השורות או המיקום הפיזי של העמודה חסרי משמעות; מה שקובע הוא הערך והמטא-דאטה (Metadata) שלו. זהו המעבר המנטלי הקריטי ביותר במסע אל עבר Finance 4.0.
🔗רוצים לדעת מה הכוונה Finance 4.0 – תציצו במאמר Finance 4.0: המעבר לארכיטקטורת ערך אסטרטגית בעידן ה-AI
גיאומטריה של מידע: למה הטבלאות שלכם צריכות להיות “ארוכות”
אחד הביטויים המוחשיים ביותר של Database Thinking הוא צורת הנתונים (Data Shape). משתמשי אקסל נוטים באופן טבעי לפרוס נתונים לרוחב כדי להקל על הקריאה – מה שנקרא Wide Table. דמיינו גיליון שכר שבו רכיבי השכר (שכר יסוד, בונוס, נסיעות) נמתחים כעמודות ימינה עד לאינסוף. מבחינה אנליטית, מדובר בסיוט: כל רכיב חדש דורש הוספת עמודה פיזית ועדכון ידני של נוסחאות הסיכום.
הפתרון טמון בפעולת Unpivot ב-Power Query, שהופכת את הטבלה לצרה וארוכה (Tall). במבנה כזה, כל רכיב שכר מקבל שורה משלו עם עמודת “סוג רכיב” ועמודת “סכום”. זה מאפשר סטנדרטיזציה (Standardization) מלאה: ניתן למפות “Base Salary” מארה”ב ו-“Fixed Pay” מצרפת תחת קטגוריית “Salary” אחת. התוצאה היא “מקור אמת אחד” שמאפשר ניתוח גלובלי אוטומטי, ללא תלות במבנה הדיווח המקומי.
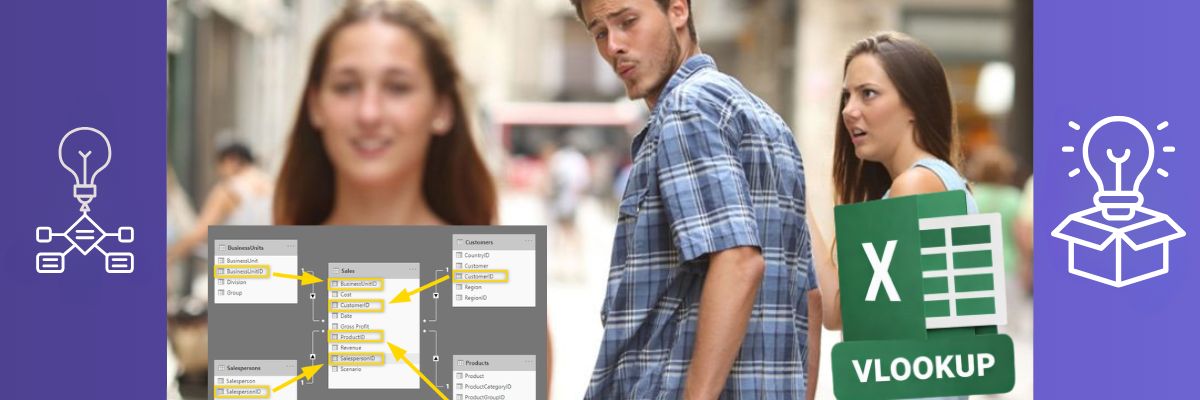
ארכיטקטורת המידע: להיפרד מה-VLOOKUP לטובת ה-Star Schema
התלות המוחלטת ב-VLOOKUP היא אולי המחסום הגדול ביותר בדרך ל-Database Thinking. הנטייה ה”אקסלית” היא להשטיח את המידע – לקחת טבלת מכירות ולהוסיף לה עשרות עמודות של שמות מוצרים ולקוחות דרך נוסחאות חיפוש. המחיר הוא קובץ איטי להחריד, שכפול מידע מסיבי וסכנה גבוהה לאי-עקביות בנתונים.
חשיבה של מסד נתונים דוגלת בנרמול (Normalization) ובבניית סכמת כוכב (Star Schema):
- טבלאות עובדות (Fact Tables): הפעלים של הארגון. הן מכילות אירועים (מכירות, תנועות יומן) וערכים מספריים.
- טבלאות מימדים (Dimension Tables): השמות. הן מתארות את ה”מי”, ה”מה” וה”מתי” (לקוחות, מוצרים, תאריכים).
במקום VLOOKUP, אנחנו יוצרים קשרים (Relationships) בין הטבלאות. מנוע ה-VertiPaq ב-Power BI יודע לנצל את המבנה הזה כדי לאחסן את המידע בצורה עמודתית (Columnar Storage). מבנה זה של נתונים מאפשר לבצע חישובים במהירות שגבוהה בסדרי גודל מהשיטה המסורתית.
השפה החדשה של הפיננסים: DAX והקשר הסינון
לימוד שפת DAX הוא האתגר הקוגניטיבי הגדול ביותר במעבר ל-Database Thinking. באקסל, הנוסחה מבוססת על קואורדינטות קשיחות (A1*B1). ב-DAX, הנוסחה היא אבסטרקטית ומתבססת על הקשר (Context).
המושג החשוב ביותר הוא הקשר סינון (Filter Context) – אוסף הפילטרים הפעילים ברגע החישוב. תחשבו על זה כעל “חלון זז”: המדד (Measure) שכתבתם יודע רק לסכם את מה שנשקף דרך החלון. אם המשתמש בחר בדו”ח שנת 2024, החלון מצטמצם והמדד מסכם רק את הנתונים הרלוונטיים. זה מה שמאפשר ליצור מדדים דינמיים כמו CALCULATE – ה”SUMIFS על סטרואידים” שמאפשר להחיל לוגיקה עסקית מורכבת על כל חיתוך זמן או אזור בלחיצת כפתור.
השכבה הסמנטית – הלב או אולי המוח של חשיבה מבוססת בסיס נתונים
השכבה הסמנטית היא המערכת הלוגית המאפשרת להפוך נתונים גולמיים למידע עסקי מוגדר וברור. במסגרת אימוץ Database Thinking, בנייה נכונה של Star Schema ושימוש מושכל ב-DAX הם רכיבים קריטיים להצלחת המודל. השילוב ביניהם מאפשר להפריד בין אחסון הנתונים לבין הלוגיקה העסקית, ובכך להבטיח מקור אמת אחד, אחיד ומדויק לכל חלקי הארגון.
🔗לפירוט נוסף על התשתית הטכנולוגית שמאפשרת ניתוח נתונים מתקדם, אתם מוזמנים לקרוא את המאמר המלא שכתבתי: Semantic Layer: הלב הפועם של ה-Finance 4.0 וניהול דאטה מודרני
אינטליגנציית זמן: איך “פסח” הופך לנתון לוגי ב-Database Thinking
אחד המקומות שבהם הגישה המסורתית קורסת הוא ניתוח על פני ציר הזמן. באקסל, “זמן” הוא לרוב רק עמודה שצריך לזוז בה ימינה או שמאלה (Offset). ב-Database Thinking, אנחנו בונים טבלת תאריכים (Calendar Table) רציפה שמכילה את כל המטא-דאטה: רבעונים, שנות כספים וחגים.
זה מאפשר לבצע השוואות “תפוחים לתפוחים” באמת. במקום להשוות את אפריל השנה לאפריל שעברה ולנסות “לנטרל ידנית” את השפעת פסח שזז, אנחנו מלמדים את המודל את הלוגיקה של החג. אנחנו יכולים להשוות את “3 הימים לפני ליל הסדר” השנה מול התקופה המקבילה אשתקד, ללא קשר לתאריך הלועזי. המודל הופך מחישוב מכני לכלי המבין מהות עסקית.
סיכום: להיות ארכיטקטים של ערך בעידן ה-AI
המעבר ל-Database Thinking הוא לא רק שדרוג של ארגז הכלים; הוא החלפת מערכת ההפעלה במוח. בעולם של Finance 4.0, התפקיד שלנו משתנה מ”מכונאי נתונים” שעסוקים בהעתקות והדבקות ל”ארכיטקטים של ערך” (Value Architects) שבונים מודלים יציבים.
בעידן שבו כולם מדברים על AI, חשוב לזכור שבינה מלאכותית היא סטטיסטית במהותה. ללא תשתית דאטה מוצקה ומבוססת Database Thinking, ה-AI עלול להפוך ל”מכונת ניחושים” במקום למכפיל כוח. כשאתם מספקים למכונה מבנה נתונים חזק ומדדים מדויקים, אתם מאפשרים לה להפיק תובנות דטרמיניסטיות ואמינות שיובילו את הארגון שלכם קדימה בביטחון מלא.
Q&A: שאלות ותשובות על Database Thinking
שאלה: האם Database Thinking אומר שצריך להפסיק להשתמש באקסל לחלוטין?
תשובה : ממש לא, אקסל הוא כלי מצוין לצריכת נתונים, אך הוא לא הכלי הנכון לניהול מודל נתונים ארגוני.
הטעות הנפוצה היא שימוש באקסל כבסיס הנתונים, הלוגיקה והתצוגה בו-זמנית. בגישת ה-Database Thinking, אנחנו משתמשים בכלים כמו Power Query ו-Power BI כדי לבנות את המודל. ואת אקסל אנחנו משאירים כ”לקוח” שמתחבר למודל הזה לצורך ניתוחים אד-הוק. כך אנחנו שומרים על הגמישות של אקסל מבלי להקריב את שלמות הנתונים והאוטומציה.
שאלה: איך Database Thinking עוזר להתמודד עם דאטה גלובלית מבוזרת?
תשובה קצרה: דרך סטנדרטיזציה של מבנה הנתונים והפרדה בין המקור הלוקאלי למודל הסמנטי המרכזי.
במקום לנסות “להדביק” טבלאות ממדינות שונות במבנים שונים, אנחנו משתמשים ב-Unpivot כדי להביא את כל המידע למבנה אחיד של שורות. ה-Database Thinking מאפשר לנו ליצור טבלאות מיפוי שמחברות בין שמות רכיבים מקומיים לקטגוריות דיווח גלובליות. כך, הוספת מדינה חדשה למערכת היא פעולה טכנית פשוטה של ניקוי נתונים, ולא שבירה של כל מבנה הדוחות הקיימים.
Database Thinking – מצורפת חוברת מלאה ומפורטת
אם הנושאים במאמר רלוונטיים לארגון שלך – ניתן לקרוא גם על שירותי הייעוץ, ההדרכה והליווי בתחום Finance 4.0 ו-AI 🚀 חדשנות ו-AI במחלקות כספים – Finance 4.0







