
Context Is the King: עכבר זה לא תמיד עכבר 💡
עולם ה-NLP (עיבוד שפה טבעית) עבר שינוי דרמטי בעשור האחרון. בעבר, מערכות ממוחשבות ניסו לפענח טקסט באמצעות כללים דקדוקיים נוקשים או רשימות מילים סטטיות, אך המהפכה הנוכחית נשענת על היכולת לייצר Contextual Embeddings המפענחים את עומק השפה. עבור מובילים טכנולוגיים וארגוניים, הבנת המנגנון הזה היא המפתח להטמעת פתרונות AI שאינם רק מרשימים, אלא באמת מדויקים ובעלי ערך אסטרטגי המניע צמיחה.
פעם חשבתם איך המודל יודע האם זה עכבר מחשב או עכבר עכבר? איך הוא “מבין” הקשר
- החתול רדף אחרי העכבר 🐭
- קיבלתי עכבר חדש למחשב 🖱️
זאת בדיוק אותה מילה, אבל ברור שהמשמעות שונה לחלוטין.
עבור המחשב, המילה “עכבר” היא בסך הכל רצף של תווים או קוד דיגיטלי. הוא לא יודע מה זה פרווה והוא לא מכיר את כפתור הגלילה. הסוד טמון בעובדה שהמודל המודרני לא מסתכל על המילה בבידוד, אלא מנתח את “השכונה” שבה היא נמצאת.
Contextual Embeddings & Attention
כאשר המודל מעבד את המשפט “החתול רדף אחרי העכבר”, הוא מפעיל מנגנון של Attention (קשב), שבוחן את כל המילים במשפט בו-זמנית. הוא מזהה שהמילה “חתול” והפועל “רדף” נמצאים בסביבה הקרובה, ולכן הוא “צובע” את המילה עכבר במשמעות הביולוגית שלה. לעומת זאת, אם המשפט הוא “חיברתי עכבר אלחוטי ללפטופ”, המודל מזהה את המילים “אלחוטי” ו”לפטופ” ומבין מיד שמדובר במוצר טכנולוגי. היכולת הזו להעניק משמעות שונה לאותו רצף תווים בדיוק היא הלב הפועם של ה-Contextual Embeddings.
הדינמיקה של ה-Context: מ-Word Vectors סטטיים ל-Contextual Embeddings
כדי להבין איך ה-LLMs של ימינו פועלים, עלינו להכיר את מושג ה-Embeddings. מדובר בתהליך שבו מילים מתורגמות לוקטורים – סדרות ארוכות של מספרים המייצגים את המיקום של המילה בתוך מרחב רב-ממדי.
העידן הישן: Word Vectors סטטיים
במודלים הישנים, לכל מילה הייתה “כתובת” אחת קבועה במרחב. המילה “עכבר” קיבלה וקטור מסוים, וזה לא שינה אם היא הופיעה במאמר על זואולוגיה או במדריך למשתמש של חומרת מחשב. הגישה הזו יצרה מגבלה קשה: המודל תמיד בחר במובן השכיח ביותר או בערבוב משונה של כל המשמעויות, מה שהוביל לחוסר דיוק בביצוע משימות מורכבות.
העידן החדש: וקטור דינמי – תלוי הקשר
מודלים מבוססי Transformer Architecture, כמו GPT של OpenAI, שינו את כללי המשחק. כאן, הוקטור של המילה אינו קבוע. הוא נוצר בזמן אמת (On the fly) תוך התחשבות בכל שאר המילים במשפט.
| הקשר | משמעות | שכנות וקטורית |
|---|---|---|
| “החתול רדף אחרי העכבר” | 🐭 חיה | קרוב ל: חתול, מכרסם |
| “עכבר חדש למחשב” | 🖱️ מכשיר | קרוב ל: מקלדת, מחשב, חומרה |
התהליך של הקשר דינאמי (Contextual Embeddings) מתבצע במספר שלבים:
Contextual Embeddings = הטבעה דינמית שמבוססת על המילים שנמצאות לפני ואחרי.
| שלב | תיאור השלב |
| Tokenization | פירוק הטקסט ליחידות קטנות המכונות Tokens. |
| Initial Embedding | הענקת ערך מספרי ראשוני לכל טוקן. |
| Self-Attention Layers | שכבות בתוך המודל שמעריכות את מידת הרלוונטיות של כל מילה לכל מילה אחרת במשפט. |
| Dynamic Transformation | שינוי הוקטור הראשוני בהתאם למשקלים שחושבו ב-Attention, כך שהמילה מקבלת את משמעותה המדויקת לפי ההקשר. |
התוצאה היא שכל מילה מקבלת זהות ייחודית בכל פעם מחדש. זה מה שמאפשר לבינה מלאכותית לכתוב שירה, לנתח חוזים משפטיים מורכבים ולסכם פגישות עסקיות בצורה שמרגישה כמעט אנושית.
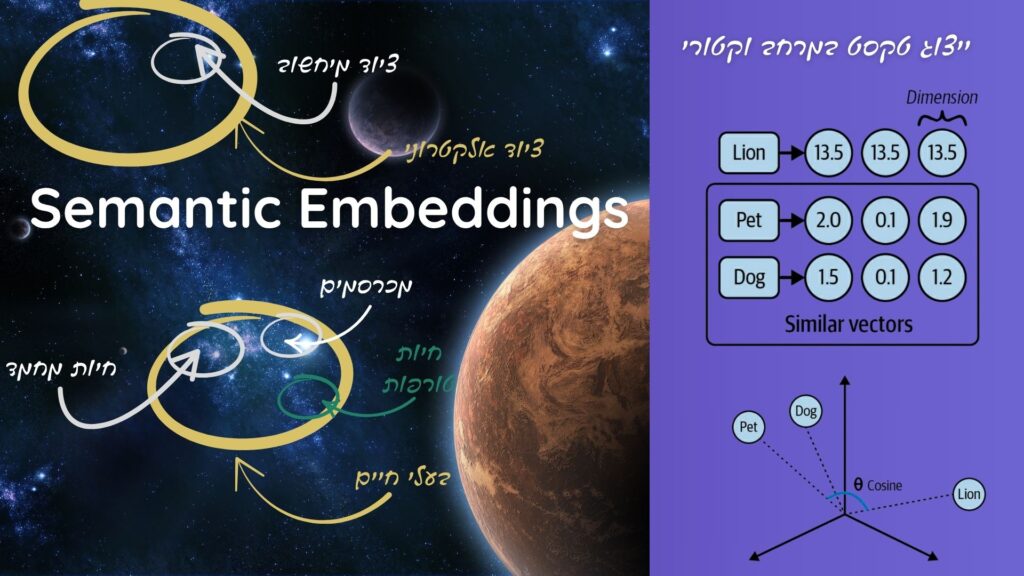
ייצוג של טקסט במרחב וקטורי – אז איך כל זה נראה בפועל? ✨
התמונה הבאה מדגימה בצורה ויזואלית איך מודל שפה “חושב” – כלומר, איך הוא ממקם מילים במרחב מתמטי לפי המשמעות שלהן.
מילים עם קשר סמנטי כמו “כלב” ו”חיית מחמד” יהיו קרובות, ומילים רחוקות במשמעות – רחוקות גם במרחב.
תחשבו על זה כמו גלקסיה של משמעויות, שבה כל מילה היא כוכב, וכל קבוצה של מושגים יוצרת מערכת משלה.
יישומים עסקיים: מעבר לתיאוריה
היכולת להבין הקשר אינה רק הישג אקדמי; היא משנה את הדרך שבה ארגונים מנהלים ידע ותהליכים, תוך דגש על צמיחה ויתרון תחרותי.
| יישום | ערך מוסף לארגון | השפעה על התוצאה העסקית |
| Semantic Search | הבנת המשמעות מאחורי המילים מעבר להתאמה מדויקת של תווים. | הצגת תוצאות רלוונטיות גם כאשר המשתמש משתמש במונחים נרדפים (למשל: “מכשיר הצבעה” מול “עכבר”). |
| RAG | שיפור הדיוק בשליפת מידע מתוך ה-Vector Database הארגוני. | שמירה על Data Integrity, מניעת הזיות (Hallucinations) והגברת האמינות של המערכת. |
| Sentiment Analysis | זיהוי ניואנסים כמו ציניות, אירוניה או סגנון כתיבה מקצועי. | ניתוח עומק של משוב לקוחות ושיחות שירות להבנת הטון הכללי של הפנייה. |
המדריך ליישום: איך מובילים שינוי מבוסס הקשר?
כדי לרתום את העוצמה של Contextual Embeddings בארגון, מומלץ להתמקד בשלושה צירים מרכזיים:
| שלב אסטרטגי | תיאור הפעולה והערך העסקי |
| אפיון נכסי הידע | מיפוי כלל המידע הבלתי מובנה (Unstructured Data) בארגון, הכולל מסמכי PDF, מיילים, פרוטוקולים של ישיבות ומדריכים טכניים. הבנת המורכבות השפתית בארגון היא הבסיס לבחירת המודל הנכון. |
| בחירת מודל ה-Embeddings | התאמת המודל לצורך המבצעי: מודלים קטנים ומהירים למשימות פשוטות, מול מודלים עמוקים (כמו OpenAI, Cohere או מודלי Open Source כדוגמת BGE) המצטיינים בהבנת הקשרים סמנטיים דקים. הבחירה מאזנת בין רמת הדיוק לעלויות המחשוב. |
| טיוב ה-Prompt Engineering | אספקת הקשר רחב בתוך ה-Prompt כדי לשפר את פעולת מנגנון ה-Attention. מעבר מפקודות כלליות להנחיות ממוקדות תפקיד (למשל: “סכם מנקודת מבטו של מנהל תפעול”) משנה את הוקטורים שהמודל יוצר ומחדדת את התוצאה. |
סיכום: העתיד שייך לאלו שמבינים הקשר
המעבר מטיפול במילים כאל נתונים סטטיים להבנה שלהן כישויות דינמיות ותלויות הקשר הוא מה שמפריד בין אוטומציה בסיסית לבינה מלאכותית יוצרת. עבור ארגונים, המשמעות היא יכולת חסרת תקדים לנתח מידע, לתקשר עם לקוחות ולקבל החלטות מבוססות דאטה.
הבנת ה-Contextual Embeddings מאפשרת לנו לבנות מערכות שלא רק “קוראות” את מה שכתבנו, אלא באמת “מבינות” למה התכווננו. זהו הבסיס לטרנספורמציה דיגיטלית ששמה את הדיוק והערך העסקי במרכז.
שאלות ותשובות – Contextual Embeddings
שאלה: מה זה בעצם Contextual Embedding?
תשובה: Contextual Embedding הוא ייצוג מתמטי של מילה הלוקח בחשבון את המילים המקיפות אותה בתוך משפט או פסקה.
בניגוד לשיטות ישנות שנתנו לכל מילה ערך מספרי קבוע, Embeddings מודרניים משתנים בזמן אמת. המודל מחשב את הוקטור של המילה בהתאם להקשר, מה שמאפשר לו להבדיל בין משמעויות שונות של אותה מילה (כמו “עכבר” חיה מול “עכבר” מחשב) ולהבין דקויות של שפה, סגנון וכוונה.
שאלה: למה הבנת הקשר כל כך חשובה עבור בינה מלאכותית בעסקים?
תשובה: הבנת הקשר היא המפתח למניעת שגיאות ושיפור הדיוק במערכות AI ארגוניות.
בעולם העסקי, מידע שגוי יכול להוביל להחלטות מוטעות. כאשר מודל מבין הקשר, הוא יכול לבצע חיפוש סמנטי מדויק יותר במסמכי החברה, לספק שירות לקוחות איכותי שמבין ניואנסים, ולנתח נתונים מורכבים מבלי להוציא דברים מהקשרם. זהו התנאי ההכרחי ליצירת אמון בין המשתמשים האנושיים לבין המערכת הטכנולוגית.
שאלה: איך אפשר לשפר את הבנת ההקשר במערכות AI קיימות?
הדרך היעילה ביותר היא באמצעות טכניקות של Prompt Engineering ושימוש במאגרי מידע וקטוריים (Vector Databases).
כאשר בונים שאילתה (Prompt), אספקת רקע רלוונטי ודוגמאות עוזרת למודל למקם את המילים בוקטורים הנכונים. בנוסף, שימוש במודלי Embedding איכותיים בתוך ארכיטקטורת RAG מבטיח שהמידע הנשלף מהמאגרים הארגוניים יהיה רלוונטי סמנטית לשאלה שנשאלה, מה שמעלה את רמת הדיוק של התוצאה הסופית.







