
אימוץ בינה מלאכותית יוצרת (Generative AI) בארגון דורש מעבר מניהול אינטואיטיבי לניהול מבוסס אמון נתונים. עבור הנהלות השואפות להוביל ארגון מונחה-דאטה (Data-Driven), הזיות במודלי שפה (LLMs) הן מחסום האימוץ המרכזי. הפער בין הביטחון העצמי הגבוה של המודל לבין הדיוק העובדתי שלו מייצר סיכון ממשי ליושרה של המידע הארגוני. המפתח לפתרון אינו ניסיון לבטל את התופעה לחלוטין, אלא ניהול סיכונים חכם המבוסס על ארכיטקטורה נכונה, בקרת איכות קפדנית ושיקול דעת ניהולי.
עבור ארגונים השואפים לקבל החלטות מבוססות נתונים (Data-Driven), הזיות במודלי שפה (LLMs) הן מחסום האימוץ המרכזי. הפער בין הביטחון העצמי הגבוה של המודל לבין הדיוק העובדתי שלו מייצר סיכון ממשי ליושרה של המידע הארגוני. המפתח לפתרון אינו ניסיון לבטל את התופעה לחלוטין, אלא ניהול סיכונים חכם המבוסס על ארכיטקטורה נכונה, בקרת איכות קפדנית ושיקול דעת ניהולי.
מהן בעצם הזיות ומה גורם להן?
כדי לנהל את הסיכון, עלינו להבין את מקורו. בניגוד למסדי נתונים מסורתיים הפועלים לפי חוקים דטרמיניסטיים, מודלי שפה הם מנועים סטטיסטיים החוזים את הרצף ההסתברותי הבא של המילים. הם אינם “יודעים” עובדות, אלא מעבדים תבניות. הסיבות המרכזיות להזיות כוללות:
- נתוני אימון מוגבלים או מוטים: המודל הוכשר על דאטה עד נקודת זמן מסוימת (Knowledge Cutoff). כששואלים אותו על אירועים מאוחרים יותר, הוא עשוי “להשלים פערים” באופן יצירתי מדי.
- Overfitting: המודל נצמד מדי לתבניות מסוימות ומשליך אותן על סיטואציות שאינן מתאימות.
- היעדר הקשר (Context): ללא חיבור למאגרי המידע הפנים-ארגוניים, המודל מסתמך על הזיכרון הכללי שלו, מה שמוביל לתשובות גנריות ושגויות.
הארכיטקטורה של האמון: מ-Black Box ל-RAG
הדרך היעילה ביותר לצמצם Hallucinations בארגון היא מעבר לשימוש ב-Retrieval-Augmented Generation (RAG). במקום להסתמך רק על הזיכרון הפנימי של המודל, אנו מחברים אותו למקורות המידע האמיתיים של החברה. אלו כוללים את מערכות ה-ERP, מסמכי ה-Internal Audit ומאגרי ה-Knowledge Management.
בתצורת RAG, המערכת מבצעת חיפוש (Retrieval) בתוך המידע הארגוני המאומת ורק אז מזינה את המידע לתוך ה-Prompt של ה-AI. בדרך זו, המודל משמש כמעבד שפה ולא כמקור המידע עצמו. זהו שינוי פרדיגמה קריטי – אנחנו לא מבקשים מה-AI להמציא תשובה, אלא לסכם ולנתח מידע קיים ומוכח.
בקרת איכות ו-Data Validation
כפי שנהוג בעולמות הביקורת והאסטרטגיה, גם בבינה מלאכותית יש להטמיע “נתיב ביקורת” (Audit Trail). שימוש בטכניקות של ניהול שלבי חשיבה (Chain of Thought) מאלץ את המודל לפרק את הלוגיקה שלו, מה שמאפשר לזהות סטיות מהאמת בטרם יוצג התוצר הסופי.
ההיבט העסקי: הערך בשימוש ב-AI אל מול סיכון (Risk Management)
אסטרטגיית ההטמעה חייבת להיות מדורגת לפי רמת הסיכון: משימות בעלות סיכון נמוך: סיכומי ישיבות או סיעור מוחות יצירתי, בהם חריגה קלה אינה קריטית. משימות בעלות סיכון גבוה: ניתוחים פיננסיים, עמידה ברגולציה (Compliance) ותחזיות תזרימי מזומנים. במשימות אלו נדרשים מנגנוני בקרה קשיחים ואימות נתונים כפול מול מקורות המקור.
הערך האמיתי (Business Value) נוצר כשאנחנו מצליחים לייצר “בינה מהימנה”. ארגון שמצליח לשלוט בהזיות בונה יתרון תחרותי – הוא פועל מהר יותר, מדויק יותר ומבוסס על תובנות עומק שהמתחרים עדיין חוששים לאמץ.

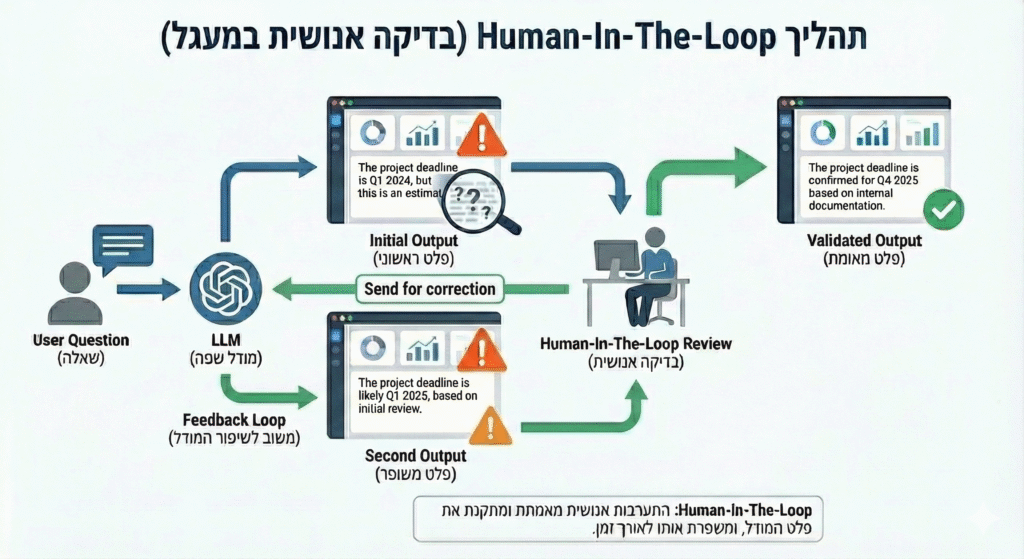
תרבות ארגונית של Human-in-the-loop
בינה מלאכותית זקוקה לבינה אנושית שתפקח עליה. גישת ה-Human-in-the-loop קובעת כי כל פלט קריטי חייב לעבור ולידציה של מומחה תוכן. תפקיד המנהל משתנה: ממבצע פעולות לבקר איכות. היכולת לשאול את השאלות הנכונות ולזהות תשובות חסרות בסיס היא המיומנות הניהולית החדשה.
התפקיד של המנהלים משתנה: ממבצעים לבקרים. אנחנו לא צריכים לכתוב את הדו”ח בעצמנו. עלינו לדעת לשאול את ה-AI את השאלות הנכונות (Prompt Engineering), ולזהות מתי התשובה “מריחה” כמו הזיה. זהו ה-Digital Management האמיתי – שילוב של הבנה טכנולוגית עם שיקול דעת עסקי.
כדי להעמיק ביכולת להנחות את המערכת ולהפחית סיכונים כבר בשלב ה-Input, מומלץ לקרוא את המאמר: הנדסת פרומפטים (Prompt Engineering) כיכולת אסטרטגית עסקית
סיכום ומבט לעתיד
הזיות הן חלק מטבעם של מודלי השפה, אך הן אינן גזירת גורל. באמצעות ארכיטקטורה נכונה (RAG), ניהול דאטה קפדני ותרבות של ביקורתיות, ניתן לרתום את הטכנולוגיה המתקדמת מבלי להקריב את הדיוק. הובלה אחראית פירושה לאמץ את החדשנות תוך שמירה על הסטנדרטים המקצועיים הגבוהים ביותר.
שאלות ותשובות
מה ההבדל המרכזי בין Hallucination לבין טעות רגילה בתוכנה?
טעות בתוכנה מסורתית נובעת לרוב מבאג בקוד או בלוגיקה קבועה, בעוד שהזיה ב-AI היא תוצר של חיזוי סטטיסטי שגוי. המודל חוזה רצף מילים הגיוני מבחינה שפתית אך שגוי עובדתית.
בתוכנה רגילה, אם תזין 1+1, תמיד תקבל 2 בגלל חוקים דטרמיניסטיים. ב-LLM, המודל מנסה לנחש מה המילה הבאה. אם הוא אומן על טקסטים שגויים או אם הוא מנסה לרצות את המשתמש בתשובה (Pleasing effect), הוא עלול לייצר תשובה שנראית נכונה אך אין לה בסיס במציאות. זהו כשל הסתברותי, לא כשל לוגי בקוד.
האם ניתן לבטל לחלוטין את תופעת ההזיות ב-AI?
ברמת המודל הגנרטיבי, לא ניתן לבטלן לחלוטין. עם זאת, ניתן לצמצם אותן לרמה זניחה באמצעות טכניקות חיצוניות כמו RAG, הגדרת רמת יצירתיות נמוכה (Temperature) וביצוע Grounding – עיגון התשובות במסמכי מקור בלבד.
איך מנהלים בתחומים רגישים יכולים להסתמך על AI?
המפתח הוא “Trust but Verify”. ה-AI משמש ככלי עזר (Copilot) לניתוח מגמות וסיכום, אך כל החלטה הקשורה לדיווחים רגולטוריים או תחזיות קריטיות חייבת לעבור ולידציה מול נתוני המקור. השימוש בטכנולוגיה מתקדמת נועד להאצה, אך שיקול הדעת נשאר תמיד בידי המנהל.
מה זה Grounding ואיך זה קשור להזיות?
Grounding (עיגון) הוא התהליך שבו אנו “קושרים” את תשובות המודל למקורות מידע ספציפיים, סגורים ומאומתים. במקום לאפשר למודל להסתמך על הידע הכללי והסטטיסטי שעליו הוא אומן – שעלול להיות לא מעודכן או שגוי – אנו מנחים אותו לפעול אך ורק בתוך גבולות הגזרה של המידע הארגוני שסיפקנו לו, כגון מסמכי חברה, מאגרי נתונים או דוחות פיננסיים.
הזיות (Hallucinations) מתרחשות כאשר המודל מנסה “לנחש” את המילה הבאה מבחינה הסתברותית ללא עוגן עובדתי מוצק. ה-Grounding פותר את הבעיה הזו על ידי שינוי מהותי בתפקיד המודל: במקום “מנוע יצירה”, הוא הופך ל”מעבד מידע” שתפקידו לסכם או לנתח דאטה קיים ומוכח.
בכך אנו מבטלים את הצורך של המודל “להשלים פערים” באופן יצירתי ומבטיחים שכל תשובה תהיה מעוגנת בעובדות הארגוניות. עבור מנהלים, זהו הכלי המרכזי המעניק ביטחון בשימוש בטכנולוגיה מתקדמת, שכן הוא הופך את תוצרי ה-AI למהימנים, מדויקים ובני-ביקורת (Auditable).








2 תגובות