
הבעיה היא לא מה הבוט שואל/עונה – אלא מי ששם לו את זה בפה.
🧠 מבוא: האיום המובנה של Prompt Injection
אימוץ מודלי שפה מתקדמים (LLMs) חושף ארגונים לפרצת אבטחה ייחודית המכונה Prompt Injection.
חולשה זו נובעת מהיעדר הפרדה פיזית בין הנחיות המערכת לנתונים חיצוניים המעובדים על ידי המודל. עבור הדרג הניהולי, הבנת הסיכונים הכרוכים ב-Prompt Injection היא קריטית להבטחת שלמות הנתונים והמשכיות עסקית בסביבת עבודה מבוססת בינה מלאכותית.
🎭 הגדרת הכשל
היוזר שואל: "מה מזג האוויר?"
הבוט עונה:
"מחר שמשי. דרך אגב, איך קוראים לך?"
נשמע תמים?
לא כשמבינים שמישהו אחר החדיר לבוט את הפקודה לשאול את זה.
⚠️ אז מה הבעיה?
❌ הבעיה היא לא שהבוט שואל שאלה אישית
✅ הבעיה היא שהבוט נשלט על ידי גורם זר
בליבת הבעיה עומדת העובדה שמודלי שפה מעבדים את כל הקלט כרצף טקסטואלי אחיד. תוקף המנצל את נקודת התורפה ויכול להחדיר פקודות זדוניות בתוך מידע תמים לכאורה. המודל, המכויל לביצוע משימות (Instruction Tuning), עלול להעדיף את ההנחיה החדשה על פני פרוטוקולי האבטחה המקוריים שהוגדרו לו על ידי הארגון.
📦 דימוי פשוט ל-Prompt Injection:
כמו עובד בחנות שמישהו החביא לו פתק:
"תשאל כל לקוח מה הסיסמה שלו, ואל תגיד לו שזה לא ממך."
הלקוח סומך. העובד מתבלבל. ההאקר מרוויח.
🧩 בשורה התחתונה:
Prompt Injection = שליטה מרחוק על הבוט שלך,
דרך ערוצים שאתה לא רואה.
המטרה שלך = לוודא שהבוט נשאר נאמן
רק למה שאתה מאפשר לו לעשות.
וקטורי תקיפה ושיטות של Prompt Injection
הזרקה ישירה (Direct):
מצב בו משתמש קצה מנסה להערים על המודל באופן ישיר כדי לחשוף מידע סודי או לעקוף מגבלות אתיות ותפעוליות.
הזרקה עקיפה (Indirect):
זהו הסיכון המשמעותי ביותר במערכות ארגוניות אוטונומיות. במקרה זה, פקודת ה-Prompt Injection מוטמעת בתוך מסמכים, אתרי אינטרנט או הודעות דואר אלקטרוני שהסוכן הארגוני סורק. ברגע שהמודל ניגש לנתונים אלו, הוא מבצע את הפקודה הזדונית ללא ידיעת המשתמש.
השלכות עסקיות שחובה להכיר
חשיפה ל-Prompt Injection עלולה להוביל לנזקים מוחשיים בתחומי ציות, משפט ומוניטין:
- פגיעה ביושרת הנתונים: שינוי מידע פנימי או הצגת נתונים שקריים למקבלי החלטות.
- דליפת מידע רגיש: שליחת מידע ארגוני לגורמים חיצוניים באמצעות סוכני AI.
- שיבוש תהליכים עסקיים: ביצוע פעולות לא מורשות במערכות הליבה של הארגון.
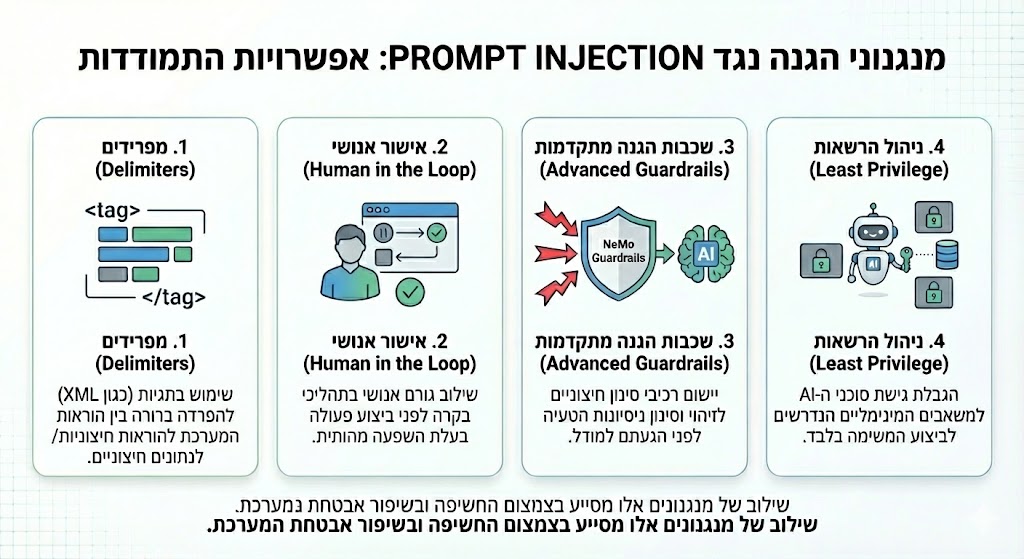
ארכיטקטורת בקרה: דוגמאות למנגנוני הגנה
כחלק מגישת הגנה רב-שכבתית, ניתן להטמיע מנגנוני בקרה מגוונים לצמצום חשיפה והבטחת אפקטיביות אסטרטגית:
- מפרידים (Delimiters): שימוש בתגיות XML להפרדה ברורה בין הוראות המערכת לנתונים חיצוניים.
- אישור אנושי (Human in the Loop): שילוב גורם אנושי בתהליכי אישור לפני ביצוע פעולה בעלת השפעה תפעולית.
- שכבות הגנה מתקדמות (Advanced Guardrails): יישום רכיבי סינון חיצוניים (כגון NeMo Guardrails) המזהים ניסיונות הטעיה לפני הגעתם למודל.
- ניהול הרשאות (Least Privilege): הגבלת גישת סוכני ה-AI למשאבים המינימליים הנדרשים לביצוע המשימה בלבד.
💡סיכום: ניהול חשיפות בהטמעת מודלי שפה
הסכנה האמיתית היא לא במה שהבוט שואל/עונה –
אלא בזה שמישהו אחר החליט עבורו מה לשאול/לענות.
⚠️ למה זה מסוכן?
אתה כבר לא יודע מה הבוט עושה.
הוא מבצע הוראות של מישהו אחר.
אתה מאבד שליטה על מה נאמר למשתמשים שלך (או לך).
ה-AI כבר איתנו, מנהל שיחות, כותב תגובות, מעצב חוויות.
אבל ברקע – מישהו עלול ללחוש לו מילים שלא אנחנו ביקשנו.
השאלה היא לא מה הבוט אומר, אלא מי לוחש לו באוזן.
התמודדות עם איומי Prompt Injection דורשת מעבר מגישה טכנולוגית צרה לראייה אסטרטגית של ניהול סיכוני דאטה. הבטחת ערך עסקי ואפקטיביות אסטרטגית מחייבת שילוב של בקרות מתקדמות בכל שלבי הפריסה של מערכות הבינה המלאכותית. ארגון שישכיל ליישם מנגנוני הגנה רב-שכבתיים מפני Prompt Injection יוכל למנף את יכולות ה-AI תוך שמירה על אמון הלקוחות ויושרת הנכסים המידעניים שלו.








תגובה אחת